在前面有提到透過 Glue Data Catalog 爬取 S3 的資料後,再透過 Athena 進行查詢
而今天要介紹 Athena 在不透過 Glue Data Catalog 的情形下如何查詢 S3 的資料
首先我們還是一樣使用 order.csv 這個檔案當作資料源,將他上傳到S3後就可以開始 Athena 的設定,切記要使用一個資料夾將檔案放在裡面
接下來我們回到 Athena 的頁面,在查詢框裡輸入以下 SQL 語法,LOCATION 的部分要記得改為你自己的 S3 路徑,其他部分保持不動就可以了
CREATE EXTERNAL TABLE athena_test (
order_id bigint,
user_id bigint,
eval_set string,
order_number bigint,
order_dow bigint,
order_hour_of_day bigint,
days_since_prior_order double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
ESCAPED BY '\\'
LINES TERMINATED BY '\n'
LOCATION 's3://it.sample.s3/SampleData/order/'
TBLPROPERTIES ("skip.header.line.count"="1")
執行後可以看到左邊的 table 區域會多出 athena_test 這張 table
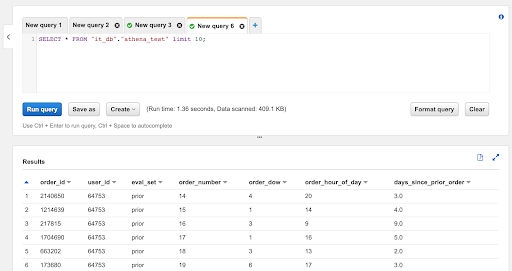
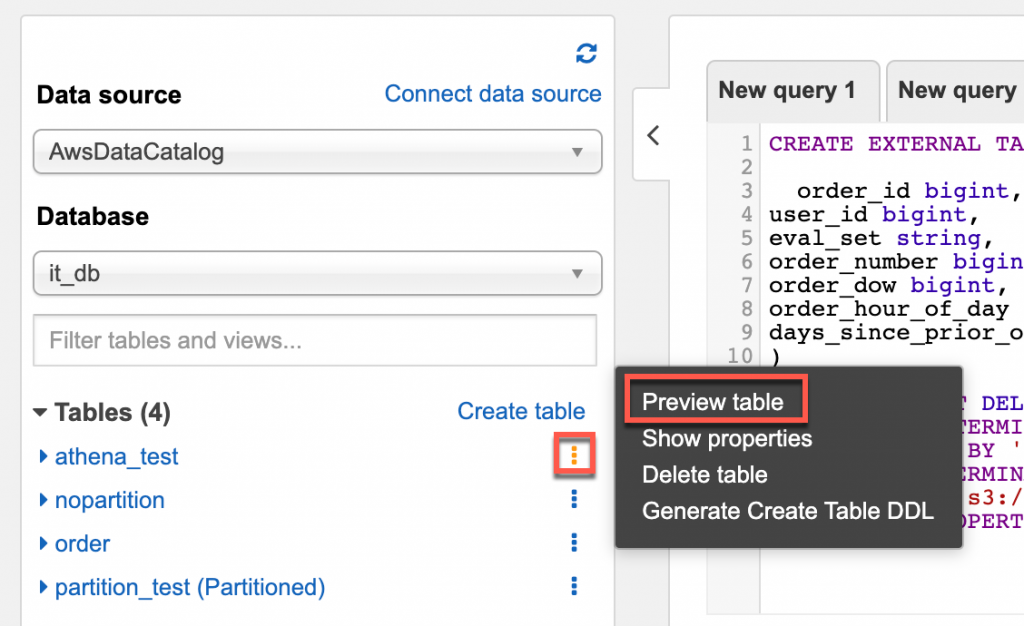
再來點選右邊的選單在點選 Preview table,試著查詢 10 筆資料,看是否可以正常顯示
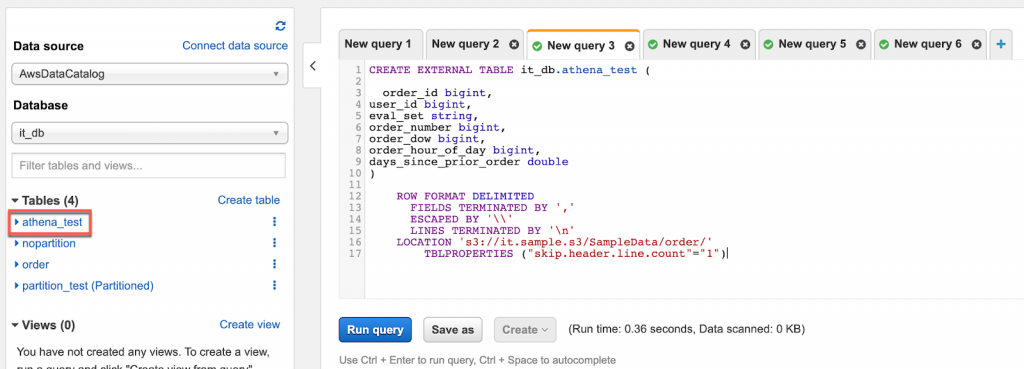
查詢成功後你應該會看到以下畫面
這個方法通常會使用在臨時需要查詢 log 或是 csv 資料時使用,例如 Apache log,今天你可能需要找出 近三天 log 中的特定IP或訪問的網址,這時 Athena 就非常的方便,只要將資料上傳 S3 並透過 Athena 創建虛擬 Table ,之後就可以使用 SQL 進行查詢得到所需的結果


 iThome鐵人賽
iThome鐵人賽